6. Consistent hashing
To achieve horizontal scaling, it is important to distribute requests/data efficiently and evenly across servers. Consistent hashing is a commonly used technique to achieve this goal.
1. The rehashing problem
Using modular hashing function to distribute requests to multiple nodes has an issue that, when you scale servers up or down, you need to move significant amount of data to match with the current hash function, if the node that is affected is storing such huge data.
The rest of the talk will discuss on the context that the hashing function is used on key-value store, in which moving large amount of data can result in the storm of cache misses.
2. Consistent hashing
Consistent hashing is designed so that when a node is down, only k / n amount of keys is redistributed, with k is the number of keys the system is storing, and n is
the number of current services. This is done by using a concept of ring.
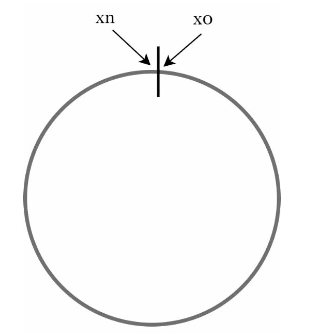
Suppose that we have a hash function that when input with a key will produce a number from x_0, x_1, … to x_n. These values are distributed
evenly on following ring.
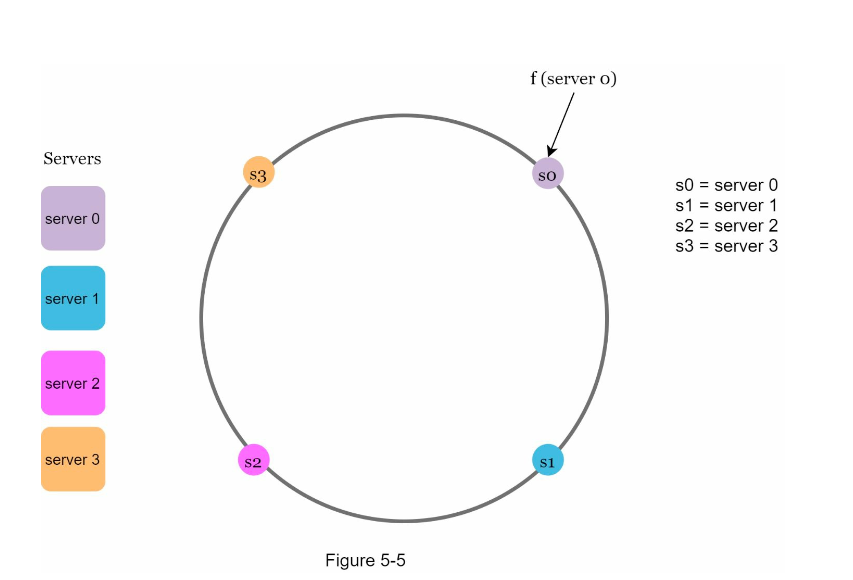
Using the hash function, we can map servers based on server IP or name onto the ring.
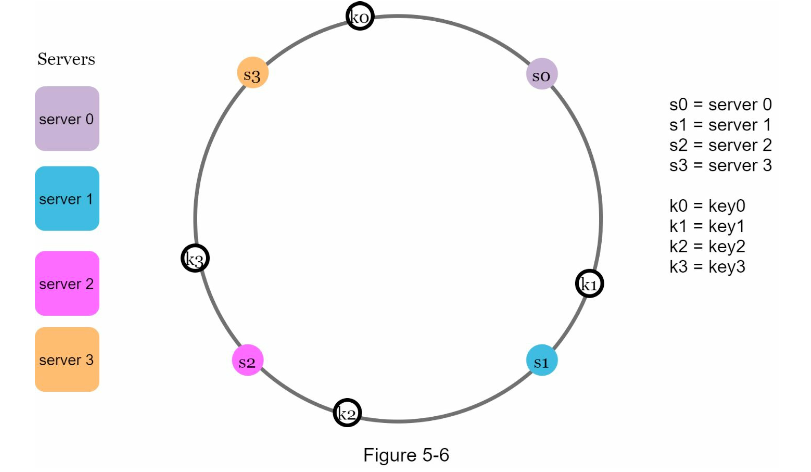
Keys are also input to produce values placed on these rings.
To determine which server a key will be stored, we first start from position of the key and go clockwise until we meet the first server. Like following img.
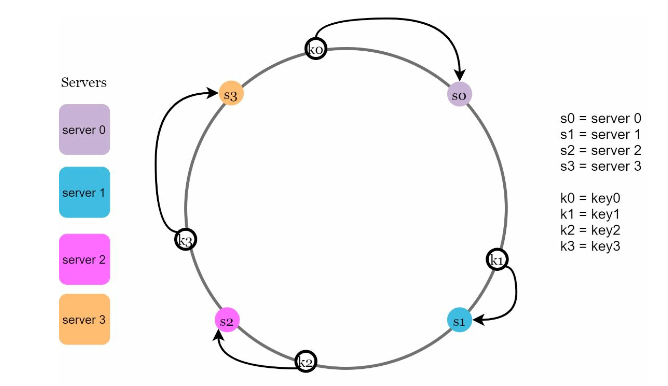
As you can image, when adding a new server, that server may be somewhere on the ring. Only portion of keys that is being on the server next to the new server we placed, more specifically the ones behind the new server, will be redistributed. Similarly, removing a server is done with the same process.
3. Issue with Consistent hashing.
Several issues on consistent hashing can be noticed are:
- Impossible to keep the same size of partitions on the ring as we remove and add servers.
- The hash function may mess up by allocating a server with a large portion. If these issues happen, we end up returning back to the rehashing problem.
We can use a technique called virtual nodes which allows us to represent a server with several virtual nodes, instead of 1 node. Like following image, each server has 3 nodes.
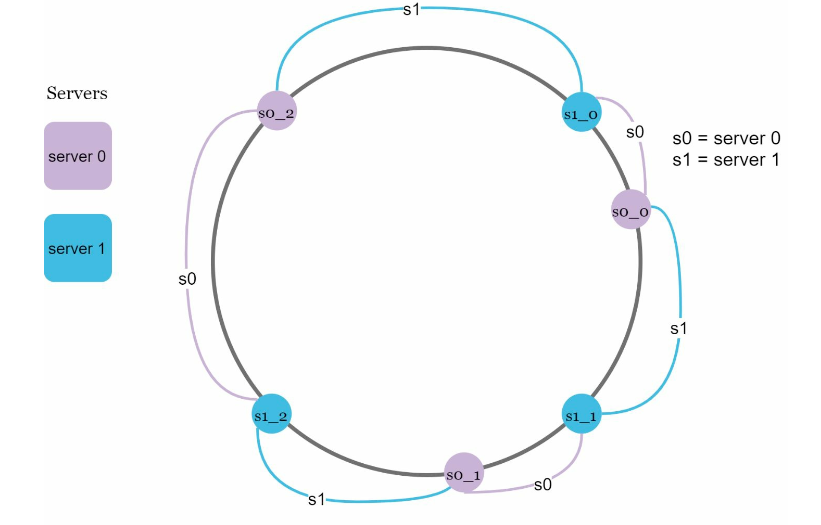
The process of choosing where to store a key is the same. The only difference is that as you add more virtual nodes for each server , the distribution of keys becomes more balanced. This is because the standard deviation gets smaller with more virtual nodes, leading to balanced data distribution. Research has experienced with the algorithm and shows that the standard deviation is 5% (for 200 virtual nodes) and 10% for (100 virtual nodes). However, with more nodes added, the more memory is used. Therefore, tuning to choose the one that fits your requirement is important.