3. Building blocks
The Java platform libraries include a rich set of concurrent building blocks , like:
- Thread-safe collections
- Variety of synchronizers, being able to coordinate the control flow of cooperating threads.
This chapter will get you covered about those concurrent building blocks.
1. Synchronized collections.
Java libraries support synchronized collection classes such as
Vector and Hashtable, part of the original JDK,
as well as their cousins added in JDK 1.2,
the synchronized wrapper classes created by the Collections.synchronizedXxx
factory methods.
1.1. Problems with synchronized collections.
Considering following static methods, for the Vector class.
| |
If we have two threads, each doing operation of these methods concurrently. Like following images
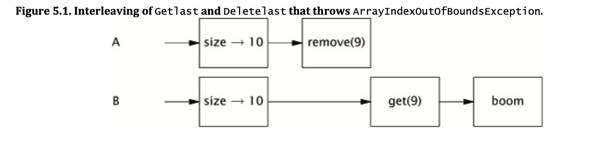
The thread calling getClass might throw ArrayIndexOutOfBoundsException,
as the size it obtained from the vector is outdated.
The same occurs for the following code, which assumes vector.size() will
not be changed.
| |
This occurs because we have to maintain the correct invariants between
the size of the vector and the underlying array of vector itself. To
address the problem, we can resort to client-side lock. For
example
| |
However, the solution above might cause the app to suffer from
performance if doSomething is a lengthy operation, or the size of
the collection is large.
An alternative to locking the collection during iteration is to clone the collection and iterate the copy instead. Cloning the collection has an obvious performance cost; whether this is a favorable tradeoff depends on many factors including the size of the collection, how much work is done for each element, the relative frequency of iteration compared to other collection operations, and responsiveness and throughput requirements.
1.2. Iterators and ConcurrentModificationException
The Iterator, which is used to iterate a Collection can fail-fast
meaning that if they detect that the collection
has changed since iteration began, they throw
the unchecked ConcurrentModificationException
But the implementation of Iterator is “good-faith effort”, hasNext()
and next() will check for a modification count which is associated with the
collection to determine if they throw the exception. However, the
modification count check is done without synchronization,
so there is a risk of seeing a stale value of the modification count
and therefore that the iterator does not realize
a modification has been made.
1.3 Hidden iterators
There might be certain cases the code implicit call iteration on the list,
like if you call print with a collection. Each element of the collection will
be iterated and the toString() method is called on it recursively. The
author of the code often forget and don’t use any synchronization for
this hidden iteration. For example
| |
The logging of set can potentially throw ConcurrentModificationException.
There are many others method that indirectly invoke the iteration such as
hashCode and equals.
2. Concurrent collections.
Many concurrent collections are introduced to replace the poor concurrency comes from synchronized collection, including:
- ConcurrentHashMap → Replacement for synchronized hash-based Map implementations.
- CopyOnWriteArrayList → Replacement for synchronized List implementations (especially when traversal is dominant).
- ConcurrentSkipListMap → Replacement for synchronized SortedMap (e.g., TreeMap wrapped with synchronizedMap).
- ConcurrentSkipListSet → Replacement for synchronized SortedSet (e.g., TreeSet wrapped with synchronizedSet). Concurrent collections are designed to be accessed by multiple threads and can offer dramatic scalability improvements with little risk.
2.1. ConcurrentHashMap
Rather than locking all operations to the Map states,
ConcurrentHashMap uses certain techniques to enhance the scalability:
Lock Striping: Dividing the map into multiple segments (stripes) with each being protected by a different lock, enabling multiple reads and writes as long as they don’t perform on the same bucket.- Improve the performance when iterating: the iteration is weakly
consistent, instead of fail-fast. Changes made to the collection
are ensured to reflect as iterating, even after
Iteratorwas constructed.
This approach has the tradeoffs that it can weaken the semantics of methods
such as size or isEmpty, because the result could be out of date
by the time it is computed.
Of course, the ConcurrentHashMap falls behind SynchronizedMap in
case you need the exclusive atomic access on the entire map.
However, ConcurrentHashMap is always consider a better solution for
concurrent access and should be the drop-in solution
2.2. Additional atomic map operations
Since a ConcurrentHashMap can not be locked for exclusive access, you can not use the client-side locking, like we
did with Vector in Solving vector synchronized problems. If you find yourself needs
operations, such as put‐if‐absent, remove‐if‐equal, and replace‐if‐equal, consider using ConcurrentMap instead,
which ensure atomic quality for these operations.
2.3. CopyOnWriteArrayList
This is a replacement of List, offering better concurrency in some common situations and eliminating the needs to
lock on the entire collection.
CopyOnWriteArrayList achieve thread safety by properly publishing the effective immutable object. Everytime the
modification occurs, the new object is created and published, allowing the old one remain immutable, which probably are
processed by other threads.
Such approach is effective if the application performs far more operations such as iteration rather than modifications. This is, in fact, popular in notification application where a set of listeners is iterated over and being notified while the new event to register is fairly rare.
3. Blocking queues and producer-consumer pattern
Producer-consumer patterns has long been popular with key benefits:
- Reduce code dependencies between consumers and producers.
- Simplify workload management, consumers and producers can perform work at different and variable rates.
The class library contains several implementations of BlockingQueue, LinkedBlockingQueue, ArrayBlockingQueue,
and PriorityBlockingQueue is a priority‐ordered queue.
There is an SynchronousQueue, which is not really a queue at all, in that it maintains no storage space for queued elements.
This queue, though is beneficial in cases where you have multiple consumers ready for the handoff, as:
- It reduces the latency of putting work into the queue (reduce I/O operations).
- Allow producers to know the state of the task when it is actually handled, unlike normal queue, where producers drop the task in a mailbox, knowing nothing about it.
3.1. Example: Desktop search
One type of program that is amenable to decomposition into producers and consumers is an agent that scans local drives (DiskCrawler)
for documents and indexes them for later searching (Indexer).
Using producer-consumer patterns in this problem offers:
- The code become more readable and reusable, each of the activities has only a single task to.
- Yields better throughput as producers don’t have to wait.
| |
Starting the Desktop search
| |
3.2. Serial Thread Confinement
To ensure thread-safety for a mutable variable, as mentioned, we can use thread confinement technique, where that object is handed off to another thread and released from the origin thread. This is particular useful for cases where deep copy is costly.
Consider this problem: You have a database connection pool that manages a limited number of database connections, which is expensive to be created. As such, it is better to allow worker threads, which request connections from the pool to execute database queries, use the connection to a particular database one by one. With thread confinement technique, you need to ensure the connection, which is mutable, is not modified by another thread.
This can be done by using blocking queues with a little more work, it could also be done with the atomic remove method of ConcurrentMap or the compareAndSet method of AtomicReference.
You should do a little exercise to practice this concept.
3.3. Deques and work stealing
Deques and work stealing is a different concurrency scheme other than work sharing, in which:
- Each thread has it own queue. Tasks, in this case, are distributed to the these queue for threads to compute.
- When a queue of it thread runs out of tasks, it steals tasks from tails of queues of other threads. The reason to steal from tails is to avoid synchronization between threads.
- A task, after being executed, may generate a number of the same tasks, which will be put in the queue of the executing thread.
Work stealing offers several benefits compared to work sharing
- Reduce contention between threads, because it minimizes the time access to the shared queue.
- Accessing to local memory of thread is faster.
4. Blocking and interruptible methods
Your code can be suspended by multiple reasons, sleeping, waiting another thread, waiting the I/O completion, etc.
These operations often throw InterruptedException if the thread is asked to be interrupted (by the main thread, or other threads).
You can also design a method to throw InterruptedException if you want long-running tasks executed by the thread to be interrupted.
Interruption is a cooperative mechanism, meaning that thread is only interrupted when it is asked, and it agrees to interrupt what it is doing at a stopping point.
When your thread is interrupted, what you should do is to do some cleanup for the thread’s task and propagate InterruptedException to
the upper methods in call stack. This can be done by:
- Catch, clean, then rethrow, or.
- If your code are being in a
Runable, you can do clean and signal the upper methods in the stack by calling interrupt on the current thread, which is calledrestore the interrupted status.
Be cautious if you are trying to ignore the InterruptedException, because you might deprive the code from upper stack of the opportunity
to act on the interruption.
5. Synchronizers
A synchronizer is any object that coordinates the control flow of threads based on its state.
All synchronizers share certain structural properties: they encapsulate state that determines whether threads arriving at the synchronizer should be allowed to pass or forced to wait, provide methods to manipulate that state, and provide methods to wait efficiently for the synchronizer to enter the desired state.
5.1. Latches
Latch is designed like a gateway. When threads come to latch, they have to wait until the gateway is open, meaning a specific conditions are met.
Like CountDownLatch, its gateway is defined as a count variable. Each thread countDown() on CountDownLatch will wait and only continue
when the count reach 0. Look at the following code.
| |
TestHarness aims to calculate the executing time when the code executing with nThreads. The startGate and endGate comes in handy
because it enables us to know when all threads are ready to start the execution, and when the last thread is done with its tasks. Measuring
time execution without latches might be hard.
You may attempt to record end in the last thread of for loop, but it might not the ending thread because the difference in the characteristics
of the task, or the degree of lock contention.
You might want to synchronize end across threads, hmm, but the performance might suffer.
The benefits of latch have numerous applications.
- Ensuring that a computation does not proceed until resources it needs have been initialized.
- Ensuring that a service does not start until other services on which it depends have started
- Waiting until all the parties involved in an activity, for instance the players in a multi‐player game, are ready to proceed.
5.2. FutureTask
FutureTask like Latch but it will allow thread to continue only the task associated with it returns a result or throws an error.
The result returned by FutureTask is guaranteed to be a safe publication.
| |
PreLoader above is an example, which uses the FutureTask to return ProductInfo asynchronously. Basically, you have to define
what the task does in Callable, define thread which is responsible to run it.
future.get() call can throw ExecutionException (which derive Throwable) which encapsulates checked,
unchecked exceptions and even Error. This means even if you throw any checked exception in Callable definition,
the result will always return ExecutionException. Because we have to always throw unchecked exception (RuntimeException), and Error
, handling exception for future.get() might be cumbersome.
launderThrowable is the utility method, which can help to make the code cleaner. This method throws immediately when the Throwable
is an Error, throws IllegalStateException if it is a checked exception (reasonable before you have to handle this exception beforehand)
, and return RuntimeException if it is unchecked one.
5.3. Semaphores
Counting semaphores are used to control the number of activities that can access a certain resource or perform a given action at the same time. Counting semaphores can be used to implement resource pools or to impose a bound on a collection.
Probably the most popular application of semaphore is a database connection pools where there are n connections for thread to get and execute the query. If the pool runs out, any thread requests will have to wait until there are connections.
Below is an example of semaphore used to restrict n login by Baeldung.
| |
5.4. Barriers
Barrier likes latch, it allows all thread to pass when all n thread reach it. However, there are several differences:
- Barriers don’t have eventual state like latch, it can be reused for the next step.
- For each step, Barrier can be set up with an operation, that will be executed before releasing all threads.
Put it in different way, Barrier waits for all threads to come while Latch waits for a condition to be met.
One implementation is CyclicBarrier, which features the same functions as mentioned above. Another noticeable point of this class is that
, once a thread wait on the barrier is either interrupted or timed out, the barrier is considered broken and all other threads will be
thrown with BrokenBarrierException, which is sensible as all threads can not come to the barrier if one thread fails.
Barrier is suitable for problems that can be subdivided and executed parallel by multiple threads. One all threads are done with their jobs , they get to the next state of the problem which is the same with the problem they have dealt with.
One another form of Barrier is Exchanger, a two-party barrier which allows parties to exchange data at the barrier point. Exchangers
are useful when the parties perform asymmetric activities, for example when one thread fills a buffer with data
and the other thread consumes the data from the buffer; these threads could use an Exchanger
to meet and exchange a full buffer for an empty one.
6. Building an efficient, scalable result cache.
The book walks you through how to build a concurrently efficient but scalable cache very intuitively. The below is the final implementation of the cache, in which:
Computable<A,V>represents an operation that has input of typeAand output of typeV.Memorizeris a cache which is also aComputable<A,V>but wrap another instance ofComputable<A,V>, to cache result using hash map.
| |
The final implementation addresses several issue
- You might first attempt to use
HashMapbut notConcurrentMap, this requires you to use client synchronization on the entireHashMap, making the cache slower, because while we can execute the operationc.computefor the missed value for a thread , but we force it to wait the computation of another thread on the different value. - You use
ConcurrentMapto address the problem, this is more efficient because we synchronize on each operation ofConcurrentMapnot the whole instance. However, there are the cases where two threads ask for a result of the same value, arrive at the same time, meet a miss cache, and start computing. This is a cpu bottleneck, because instead of both executing the long operation, we can enhance by making a thread wait on another thread computation’s result. FutureTaskcomes in handy in this case. It allows you to wait the result of another thread. However, there is still small chance that two threads executing the operation at the same time without waiting the result of the other if you don’t make put-if-absent operation of theConcurrentMapatomic. Usingcache.putIfAbsent(arg, ft)in the line 16 addressing this.
That is the end of the chapter…… I get so excited to use principles and tools of this chapter to build real things in the next chapter. Happy learning all ^_^.